主机环境8GB,操作系统Manjaro,Python3.6.6 , Django2.2
之前用whoosh+haystack+jieba实现的搜索,感觉速度不是特别快,这次学习下elasticsearch+haystack+ik实现搜索功能。
elasticsearch是一个分布式的搜索引擎,支持集群,部署在不同的机器上。同时支持分词插件,比如ik分词,可视化插件kibana等。
我所理解的elasticsearch主要的原理:
首先在自己程序中配置要产生索引的表字段和指定索引库,然后根据这些字段,创建索引数据结构,保存在es中的索引库中,借着通过API根据关键字从指定的索引库中查找结果,以JSON格式返回,然后根据这些结果再去数据库中查找相应的记录,最终对这些查询集序列化,返回给前端。
es主要解决了数据库在模糊查询关键字的时候,会忽略所建立的索引,从而导致大数据量的查询效率低的问题。
一 安装elasticsearch
1.安装JAVA虚拟机,这个就不说了
2.去官网找到网址,命令行
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.1-linux-x86_64.tar.gz
3.然后解压到制定目录
tar -zxvf elasticsearch-7.8.1-linux-x86_64.tar.gz -C /opt/elasticsearch ,-C表明指定具体解压的目录。
因为我的是manjaro操作系统,自带了包管理器pacman,直接sudo pacman -S elasticsearch,一键安装。不过pacman的软件库中的elasticsearch没有官网的版本新。
二 配置elasticsearch
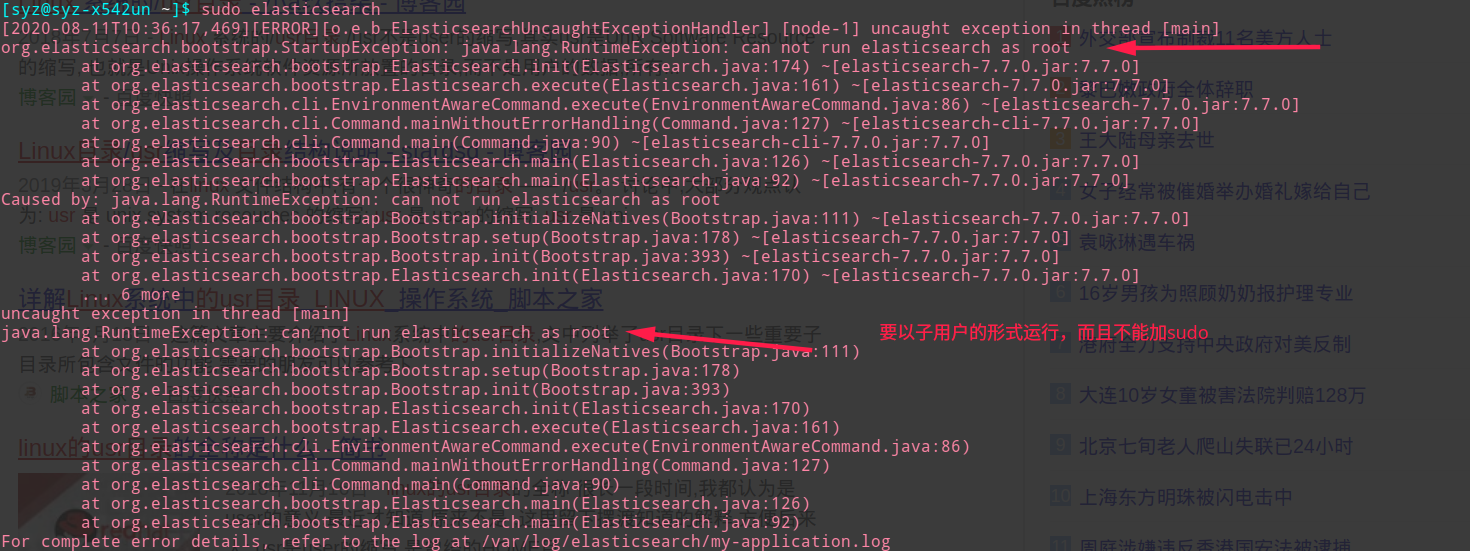
1.创建非root用户
因为elasticsearch默认不能使用root角色启动服务,所以需要创建另外的用户。创建用户的指令
useradd syz
password syz
使用sudo su syz进入相应的用户下
这一步因为我的manjaro做了主系统,一开始就已经设置了一个不是root的用户,所以这一步是跳过的,如果已经有了非root用户,则可以不用在创建新的用户。直接将elasticsearch相关文件的所属用户或组修改成非root就可以操作了。
2.配置elasticsearch.yml
找到自己elasticsearch目录下的elasticsearch.yml,进入其中修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # es的集群名
cluster.name:my-application
# es结点值
node.name:node-1
# 数据存放的地方
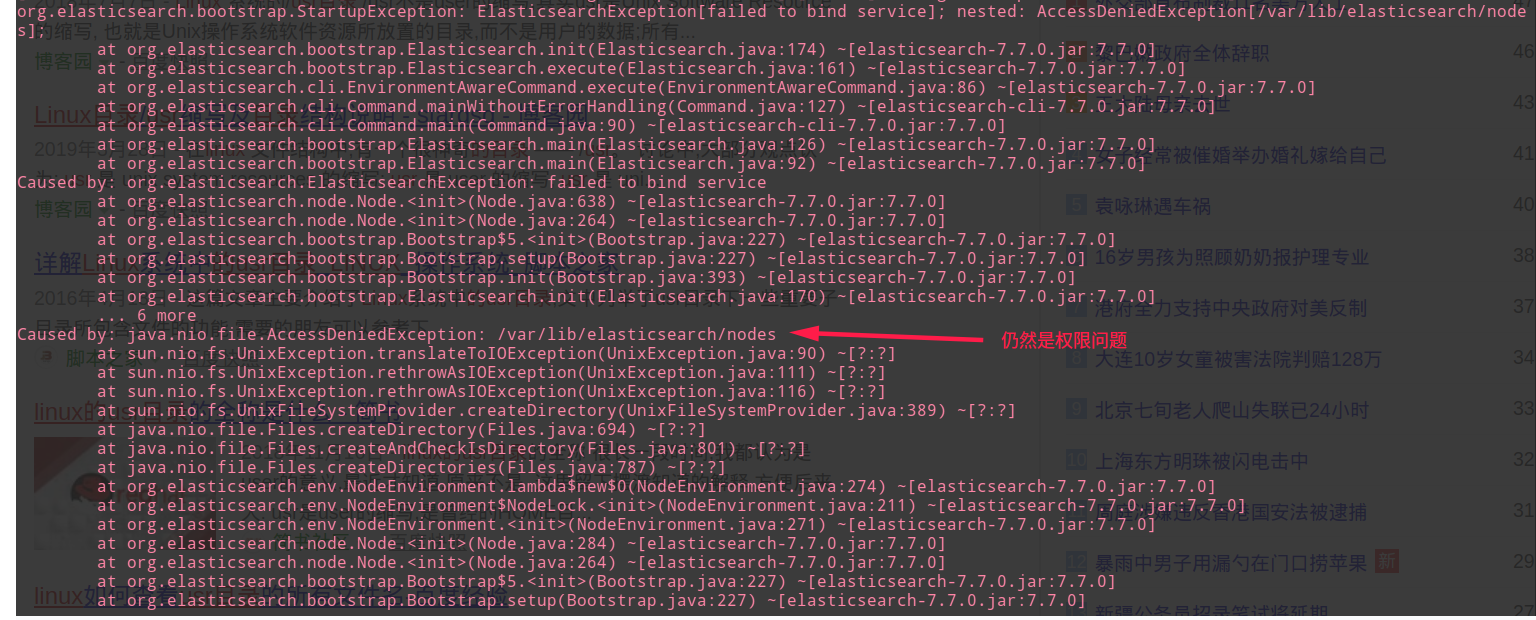
path.data:/var/lib/elasticsearch
#日志存放的地方
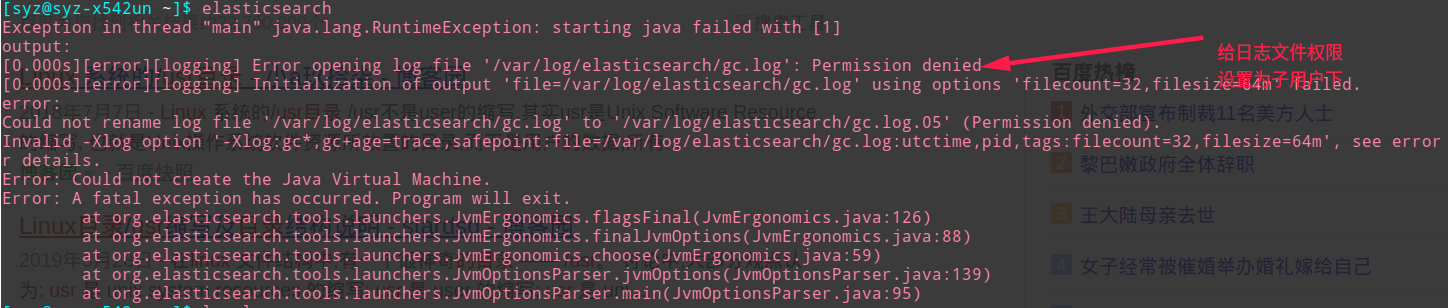
path.logs:/var/log/elasticsearch
# 自己的ip地址
network:192.168.0.105
# 端口号
http.port:9200
bootstrap.memory_lock:false
bootstrap.initial_master_nodes:false
|
3.启动elasticsearch
进入其bin目录。
./elasticsearch
后台运行:./elasticsearch -d
三 启动elasticsearch遇到的一些错误汇总
 {width=90%}
{width=90%}
 {width=90%}
{width=90%}
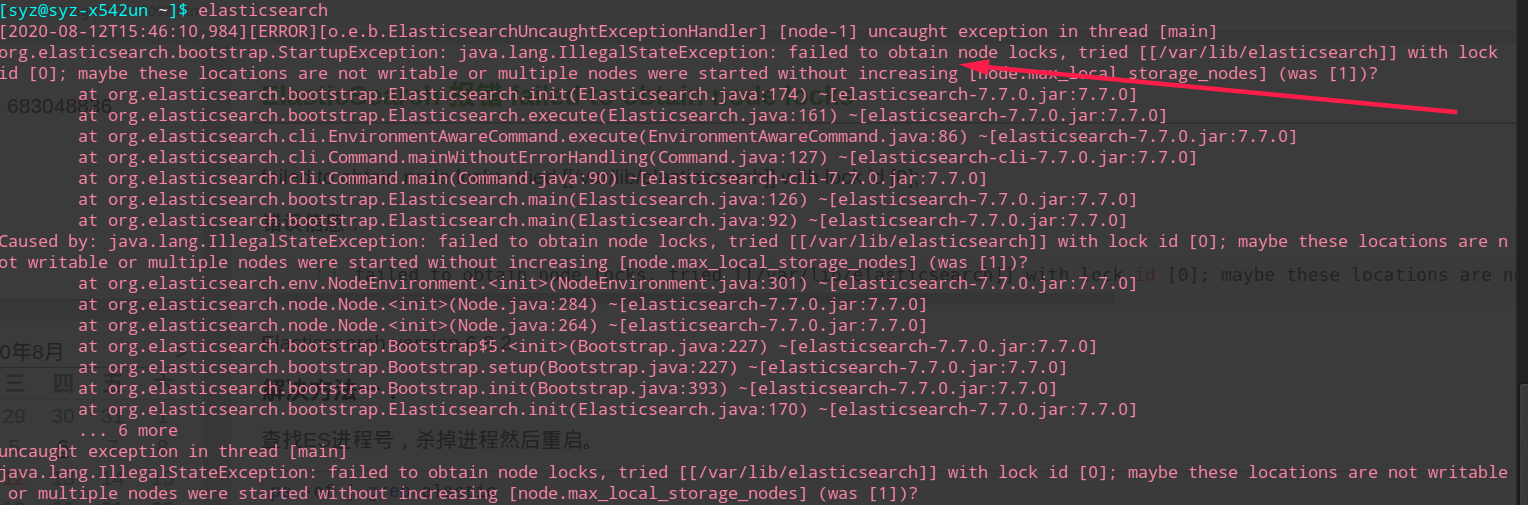
说明:这个表示当前以运行的服务器结点个数达到上线,我出先这个问题的原因是之前已经启动了一个结点,启动失败了,然后再次启动就会出错。解决方法是kill掉之前启动不成功的结点,重新启动。
 {width=90%}
{width=90%}
 {width=90%}
{width=90%}
 {width=90%}
{width=90%}
四 在Django的前后端分离中对接elasticsearch
以下是吐嘈:
这地方,按照原始的思路,打算使用DRF对接elasticsearch,但是使用过程中也是出现了蛮多的问题。例如使用drf-haystack序列化searchset,返回的结果竟然是空,我用curl直接查找索引库可以查找到数据。
使用drf-haystack对接whoosh搜索引擎,虽然返回了结果,但是却返回了所有的结果,不同的关键字,返回同样所有的结果集。
忙了一天,百度浏览了博客,基本上都一模一样,没有一个人出了问题,大多数只是表面的对接了一下,我就纳闷了?是版本冲突还是啥?具体也不晓得之后也去了github上查看,fork和star的人好少,估计也不怎么维护,所以最终决定放弃drf-haystack,还是自己写个类来在内部请求es,然后解析json,在去hit数据库,拿到对应的结果集,最后序列化给前端。
先上代码,因为昨天实现好对elasticsearch的操作类,写的可能不够完善。不过基本的根据关键字查找到对应的索引结果,是可以实现了。一些复杂的工程还需要去学习es的一些API参数,以满足不同的场景。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
|
class CommoditySearchOperation(GenericAPIView):
"""ES搜索操作"""
index_models = [Commodity]
serializer_class = CommoditySerializer
pagination_class = CommodityResultsSetPagination
elastic_class = ElasticSearchOperation
def get_elastic_class(self):
return self.elastic_class
def get_elastic(self, *args, **kwargs):
if getattr(self, 'elastic', None):
return getattr(self, 'elastic')
elastic_ = self.get_elastic_class()
setattr(self, 'elastic', elastic_(*args, **kwargs))
return self.elastic
def get_queryset(self):
elastic = self.get_elastic(request=self.request)
return elastic.get_queryset()
def get(self, request):
queryset = self.get_queryset()
common_logger.info(queryset)
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
class CommoditySerializer(serializers.ModelSerializer):
"""商品序列化器"""
class Meta:
model = Commodity
fields = '__all__'
class ElasticSearchOperation:
"""直接对es的请求封装"""
Model = Commodity
BASE_URL = 'http://192.168.0.105:9200/'
FUNC = '_search'
INDEX_DB = 'shop'
def __init__(self, *args, **kwargs):
for key, value in kwargs.items():
setattr(self, key, value)
def combine_url(self):
assert hasattr(self, 'request'), 'Should include request '
if hasattr(self, 'url'):
return self.url
query = self.request.query_params.copy()
query.pop('page')
url = self.BASE_URL + self.INDEX_DB + '/' + self.FUNC + '?' + '&'.join(
['q=' + key + ':' + value for key, value in query.items()])
setattr(self, 'url', url)
common_logger.info(url)
return url
def get_search_results(self):
if hasattr(self, 'pk_list'):
return self.pk_list
url = self.combine_url()
response = requests.get(url).json()
hits = response.get('hits').get('hits')
pk_list = [int(document.get('_source').get('django_id')) for document in hits]
setattr(self, 'pk_list', pk_list)
common_logger.info(pk_list)
return pk_list
def get_queryset(self):
"""根据索引结果查询数据库"""
assert hasattr(self, 'Model'), 'Should define Model'
pk_list = self.get_search_results()
ordering = 'FIELD(`id`, {})'.format(','.join([str(pk) for pk in pk_list]))
return self.Model.commodity_.filter(pk__in=pk_list).extra(select={"ordering": ordering}, order_by=("ordering",))
|
说明:我没有去仔细看drf-haystack的代码,只是利用了es向外提供了Restful的Api。为了不暴露自己的ip和端口号。加了一层视图封装一下。
基本流程:前端请求GET方法到后台,后台获取GET的参数。然后通过这些参数,拼接成请求es索引库的url,发送GET请求,获取JSON格式的结果,对其解析,解析出model的id,随即利用extra制定其结果集的顺序(这里需要制定),不然queryset返回的是按id从小到达的,而不是按照es返回的按照score排列的结果集了。最后,将这些queryset进行序列化,添加分页器等等,将结果返回给前端。
存在的几个问题,记录下,下次需要解决:
1.es每次hit索引库,只返回了10条结果,如何让它一次返回更多的数据。
2.我的这种方法性能上是否还需要提高?
其实,Python中存在elasticsearch包,可以创建多重模式的elasticsearch,并提供丰富的Client和API,以后使用到的时候,我再学习并写篇笔记!今天就到这里。
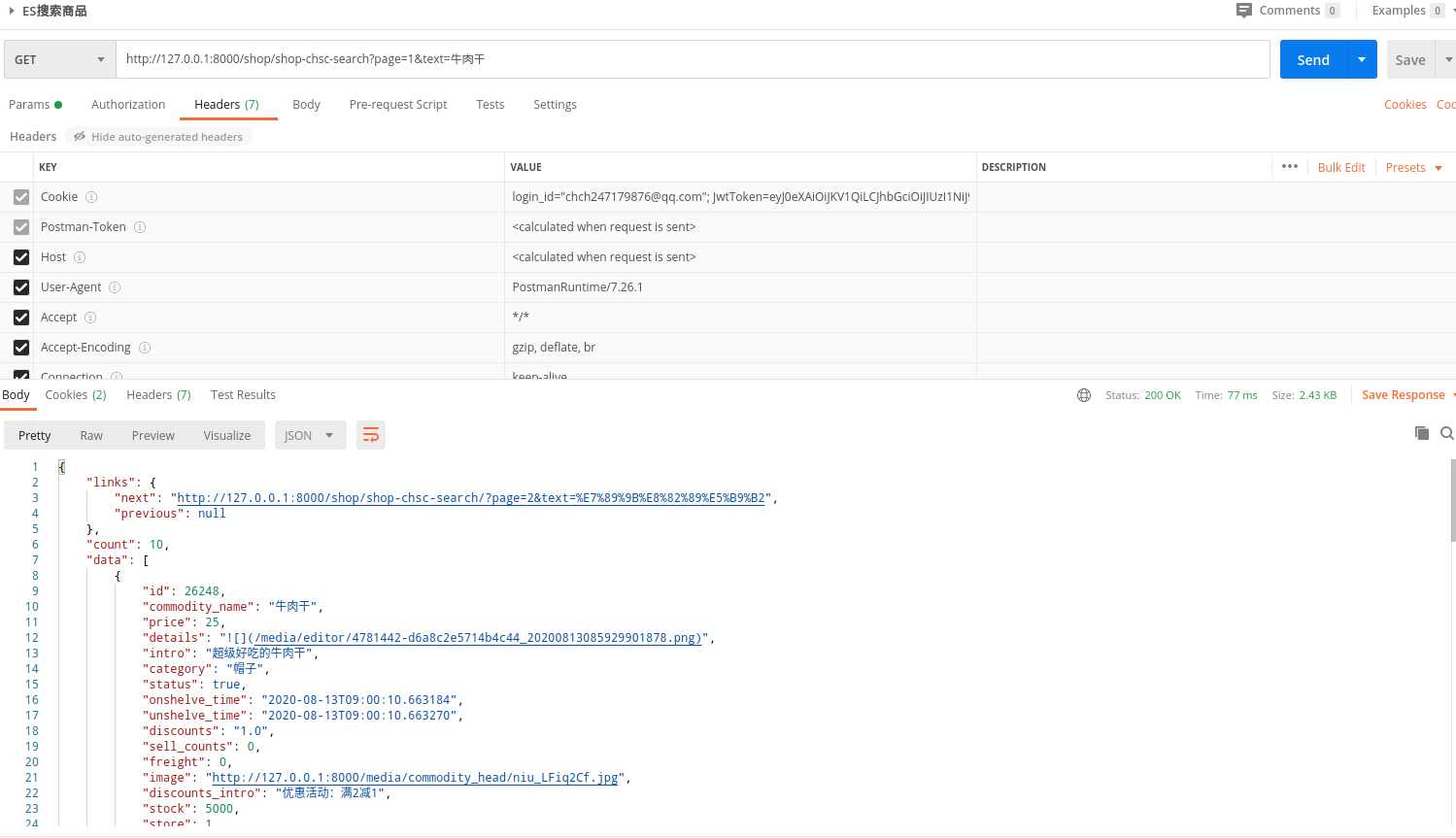
五 返回的结果示例:
 {width=90%}
{width=90%}