学习rabbitm今天学习了rabbitmq的持久化和消息分发的简单原理和简单demo.做个笔记记录下
Four —–持久化Durable
之前学到了consumer(worker)挂掉了,可以通过消息确认机制实现rabbitmq服务的重新转发.但是如果rabbitmq服务自己也突然挂掉了,怎么办呢?根据以往学过的redis,我们可以很容易想到可以将数据在每次操作指令后将其以RDB或AOF的形式持久化到磁盘;而rabbitmq也有自己的持久化机制.
1.通过标记queue和messages为可持久化的来告诉rabbitmq.(注:对于已经存在的同名且未声明持久话的queue,对其重新定义durable无效.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
def callback(ch, method, propeties, body):
print("Received %r" % body.decode())
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue='task_queue',on_message_callback=callback)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
channel.basic_publish(exchange='',
routing_key="task_queue",
body='syz666',
properties=pika.BasicProperties(
delivery_mode = 2,
))
channel.close()
|
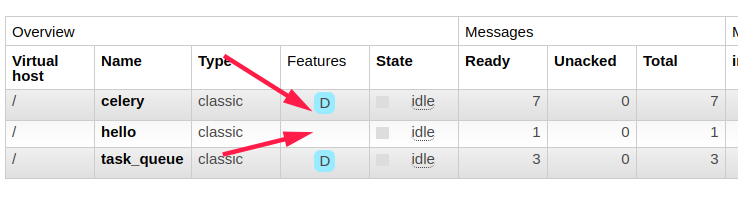
结果:
 {width=100%}
{width=100%}
hello队列不是可持久化的,task_queue和celery是可持久化的
 {width=100%}
{width=100%}
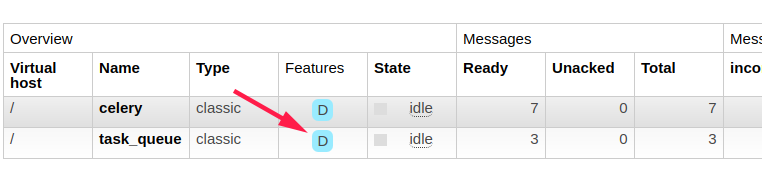
重启rabbitmq后
 {width=100%}
{width=100%}
重启rabbitmq后,非持久化的队列和消息都被清空了,因为其占用的内存空间被回收.
Five —-消息分发 Dispatch
Five —- 消息分发公平性
rabbitmq默认情况下,并不会公平的分发消息到空闲的consumer,因为默认情况下rabbitmq是在消息进入到队列后,才会分发消息,因此此时并不会知道每个consumer还有多少个消息未处理,依然将第N个消息发送给对应的第N个consumer.因此就会产生某个consumer很忙(未处理完当前,又收到消息了),而其他的consumer很闲(当前很闲且还没有接收到消息.
解决方案:
1.使用basic.qos协议方法来告诉rabbitmq不要同一时刻给一个工作者超过一条以上的消息.换句话来说,就是不会将消息发送给正在处理的consumer,而是那些不繁忙的consumer.
2.当然,如果恰巧所有queue都填满了,并且所有的consumer都在忙,那么此时需要增加更多的consumer(可以通过集群方式)来加快处理速度,或者为每个消息设置存活时间TTL,来减缓处理的压力.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import pika
import time
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body.decode())
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
channel.start_consuming()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message1 = '水人波浪形态'
message2 = '第一滴血!'
channel.basic_publish(
exchange='',
routing_key='task_queue',
body=message1,
properties=pika.BasicProperties(
delivery_mode=2,
))
channel.basic_publish(
exchange='',
routing_key='task_queue',
body=message2,
properties=pika.BasicProperties(
delivery_mode=2,
))
connection.close()
|
 {width=100%}
{width=100%}
 {width=100%}
{width=100%}
说明:
上图中启动了两个consumer进程,因为设置了prefetch_count=1,即每个consumer统一时刻只接受一个message,因此统一时刻发送两个message到队列中,两个consumer会分别处理其中一个,待处理完再处理其他message.