1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
| from typing import *
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
class Perception(object):
def __init__(self,
n_features: int,
iter_counts: int,
n_samples: int,
category: int,
):
self.iter_counts = iter_counts
self.n_samples = n_samples
self.learning_rate = 1
self.n_features = n_features
self.category = category
self.w = 0
self.b = 0
self.x = None
self.y = None
self.pot_size = 10
self.errors = []
def generate_data(self):
"""
数据生成
"""
my_data = datasets.make_blobs(n_samples=self.n_samples,
n_features=self.n_features,
centers=self.category,
center_box=(-10, 10)
)
self.x, self.y = my_data
for idx, y in enumerate(self.y):
if y == 0:
self.y[idx] = -1
@staticmethod
def cal_y(data: np.ndarray, w: np.ndarray, b: int):
"""
计算wx + b
"""
return np.dot(data, w) + b
def generate_gram(self) -> List[List[float]]:
"""
生成gram矩阵
"""
z = np.transpose(self.x)
gram = np.dot(self.x, z)
return gram
def train_origin(self) -> Tuple[np.ndarray, float]:
"""
原始形式
"""
self.errors = []
w = np.random.rand(self.n_features, 1)
b = 1
i = 0
while i < self.iter_counts:
error = 0
for j in range(self.n_samples):
xj, yj = self.x[j], self.y[j]
y_value = self.cal_y(xj, w, b)
if yj * y_value <= 0:
error += 1
w += self.learning_rate * np.expand_dims(xj, 1) * yj
b += self.learning_rate * yj
self.errors.append(error)
if error == 0:
break
i += 1
if i == self.iter_counts:
print(f"在{self.iter_counts}有限迭代次数中总存在误分类情况")
self.w, self.b = w, b
return w, b
def train_dual(self) -> Tuple[np.ndarray, float]:
"""
对偶形式
"""
self.errors = []
gram = self.generate_gram()
a, b, i = np.zeros([self.n_samples, 1]), 0, 0
while i < self.iter_counts:
error = 0
for j in range(self.n_samples):
yj = self.y[j]
y_value = np.dot(gram[j], a * np.expand_dims(self.y, 1)) + b
if yj * y_value <= 0:
error += 1
a[j] += self.learning_rate
b += self.learning_rate * yj
self.errors.append(error)
if error == 0:
break
i += 1
if i == self.iter_counts:
print(f"在{self.iter_counts}有限迭代次数中总存在误分类情况")
w = np.zeros([2, 1]).flatten()
for j in range(self.n_samples):
w += a[j] * self.y[j] * self.x[j]
self.w, self.b = w, b
return w, b
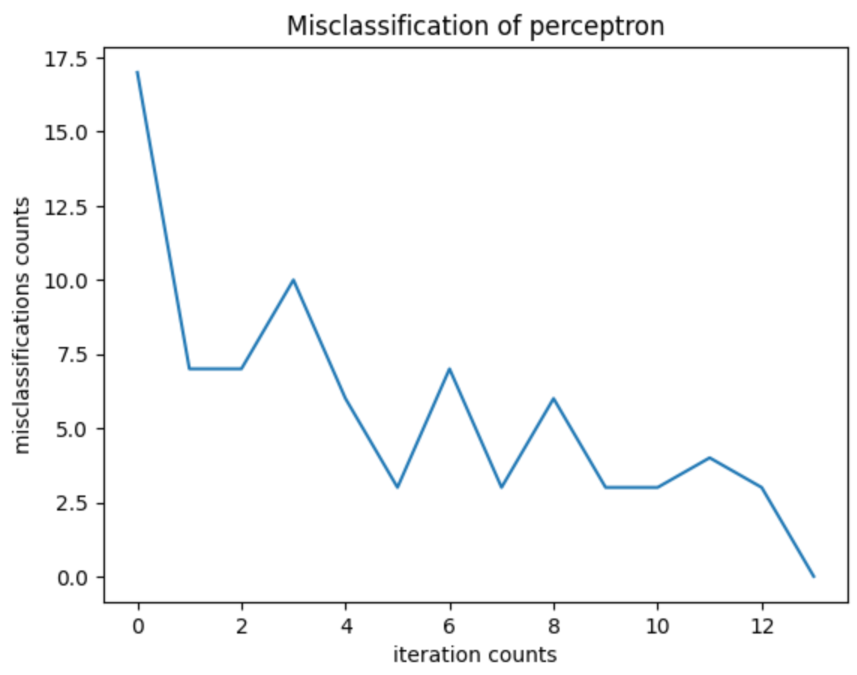
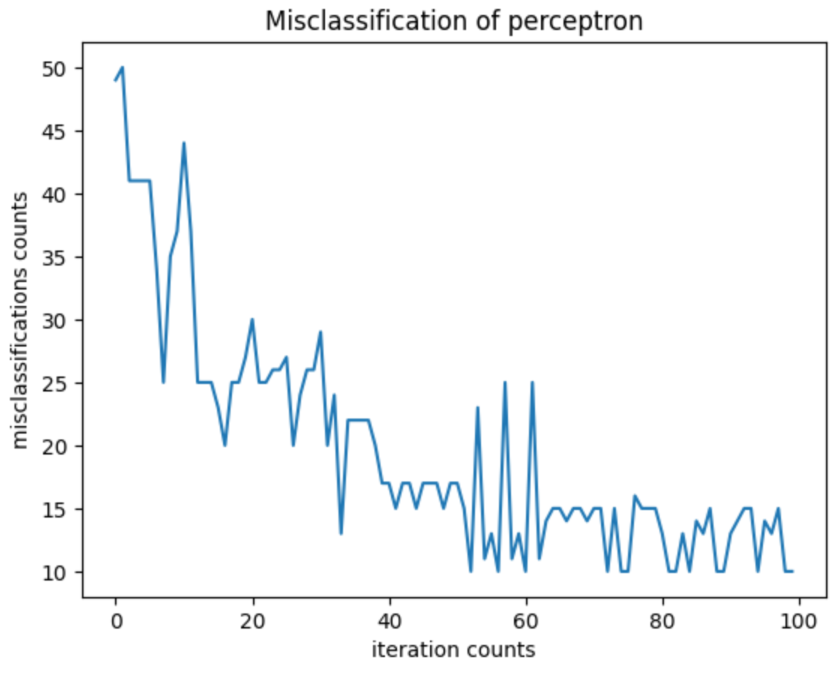
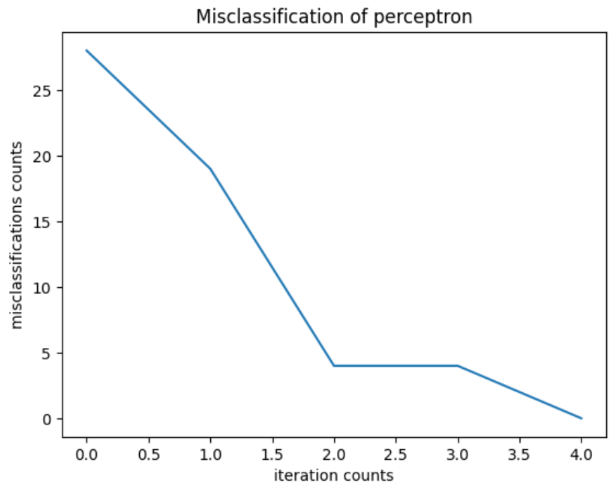
def error_gui(self):
"""
每次迭代的误分类次数---折线图
"""
print(f"参数w: {self.w.flatten()}, b: {self.b}", )
print("迭代次数:", self.iter_counts)
fig = plt.figure()
ax = fig.subplots(1,1)
ax.set_title('Misclassification of perceptron')
ax.set_xlabel('iteration counts')
ax.set_ylabel('misclassifications counts')
ax.plot(range(len(self.errors)), self.errors)
plt.show()
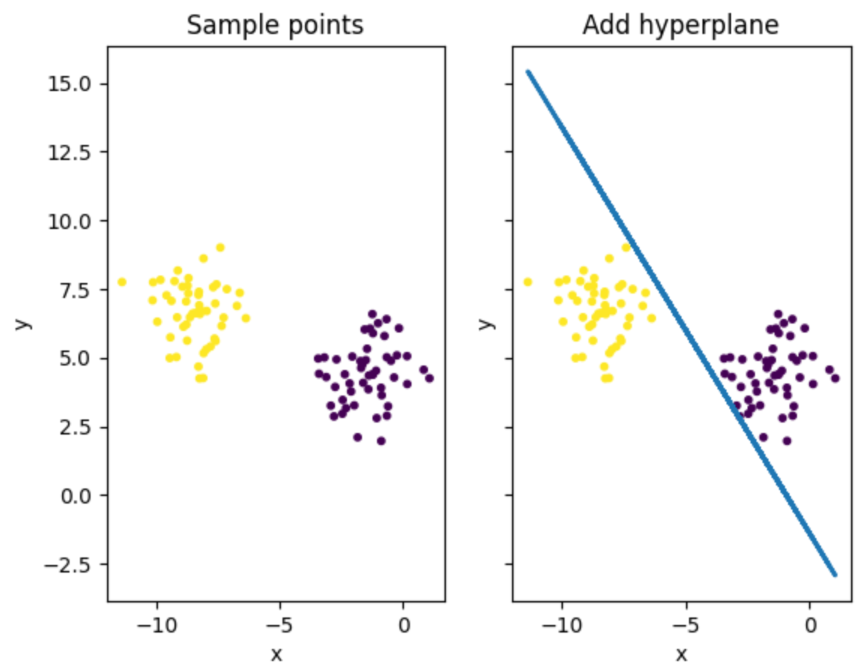
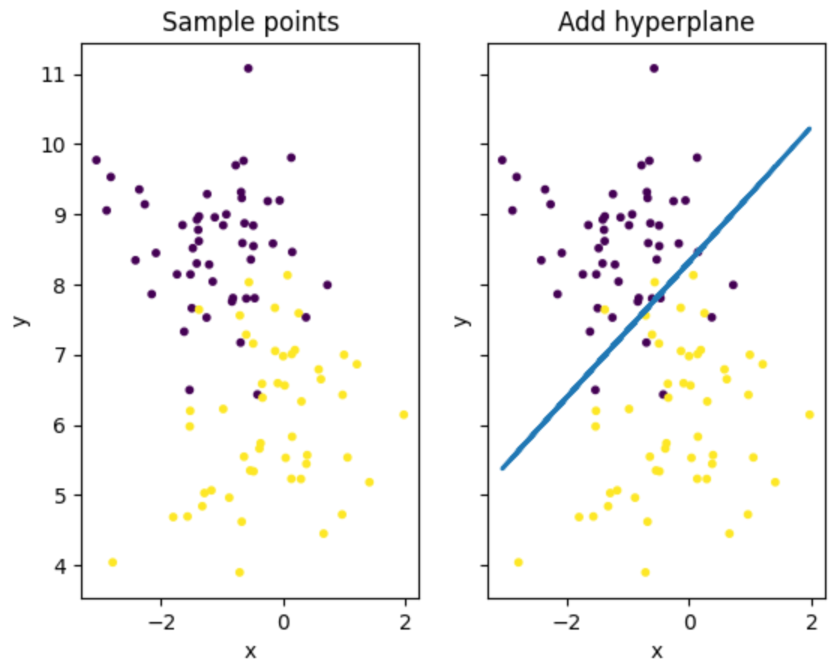
def hyperplane_gui(self):
"""
训练出来的超平面
"""
fig = plt.figure()
ax1, ax2 = fig.subplots(1, 2, sharex=True, sharey=True)
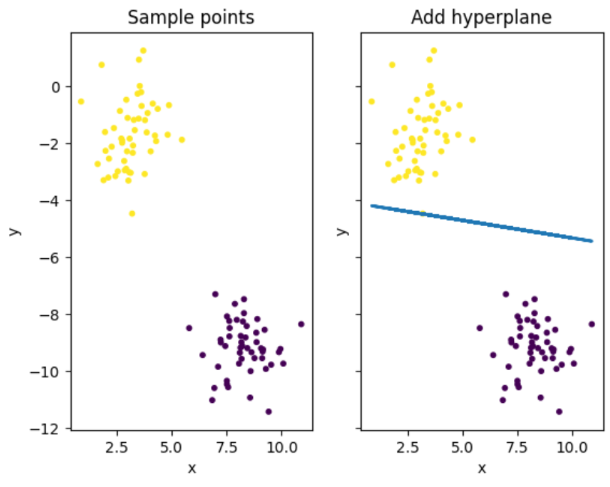
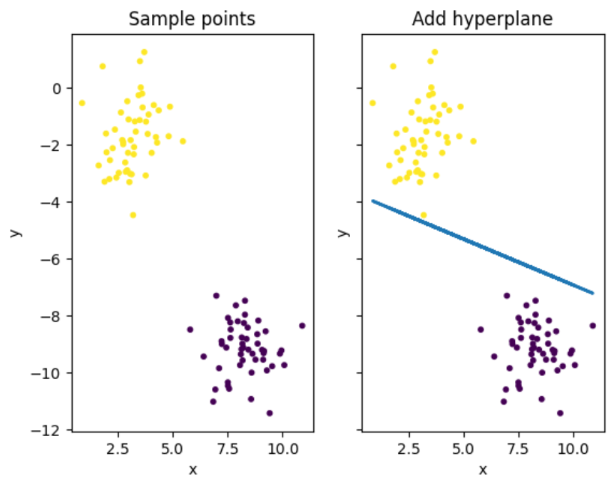
ax1.set_title('Sample points')
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax1.scatter(self.x[:, 0], self.x[:, 1], c=self.y, s=self.pot_size)
ax2.set_title('Add hyperplane')
ax2.set_xlabel('x')
ax2.set_ylabel('y')
ax2.scatter(self.x[:, 0], self.x[:, 1], c=self.y, s=self.pot_size)
ax2.plot(self.x[:, 0], (-self.b - self.x[:, 0] * self.w[0]) / self.w[1], linewidth=2.0)
plt.show()
def run(self, use_dual: bool = False) -> None:
if use_dual:
self.train_dual()
else:
self.train_origin()
p.error_gui()
p.hyperplane_gui()
|